
Cryptography terms like encrypted, encoded, and hashed are often incorrectly thrown around and misused. As someone who has been responsible for managing Compensation, HR, and Payroll IT systems one way or another for the past ten years at FedEx, I have a lot of experience protecting data. Part of my responsibilities has been to help my business partners understand the difference in these concepts and the value of each. In this article, I’m going to share some of my favorite concepts and in what context they apply.
By the end of this article, you will have a basic understanding of these terms:
- Encrypted
- Hashed
- Encoded
- Obfuscated
- Scrambled
- Salted
- Peppered
Data security starts with storing the data securely. These are common cryptography concepts that are used to protect data at rest.
Encryption
Cryptography is the science of using mathematics to encrypt and decrypt data. That was the definition that was coined by Phil Zimmermann (the creator of PGP – one of the first widely used methods of sending encrypted emails and encrypting sensitive files). Cryptanalysis is the science of recovering the original data access after it was encrypted – without the method of encrypting.

So, what’s encryption? Encryption is the cryptographic process of converting data from a readable (by people or computers) to a non-readable format and then a process to convert it back to a readable state. This is typically done now via an encryption key. A common way is a pair of keys – one private and one public. As the consumer of encrypted communications, you generate a public and private key. You then provide a public key to everyone you want to send encrypted data to you (a message for example). You can openly share this key with as many people as you wish without worrying about anyone consuming data that is encrypted for your use. The purpose of the public key is only to encrypt the data. In order to decrypt the data, you need the private key. This is aptly named as you don’t share the private key with anyone. Anyone can send you data that’s encrypted and you are the only person who can decrypt this data.
This is a very common methodology as it is simple to implement and very convenient. A company (like a bank) can easily roll out a new key by generating a new private key and sending out the public key to all of their partners who send them data (and they all share the same public key).
There is a pretty nifty demo of this process here. The demo will generate a public and private key and then let you encrypt and decrypt messages.
Encoding
Computers can only store 1s and 0s (also known by people as true/false, on/off, etc). Counting by 1s and 0s is also known as a base-2 counting method. We (humans) like to count by 10s (since we have 10 fingers) which is base-10. However, I should point out that technically, base-10 is counted from 0-9, not 1-10. Computers like to count by just 0s and 1s which are known as bits. Long story short, this goes back to vacuum tubes and relays. Essentially it is the flow of electricity (1s) or the absence of it (0s).

We care about all of this because if computers can only store bits (0s and 1s), how do we end up with pictures, email, video, and everything else we store on our computers? That’s where the magic of encoding happens. The encoding scheme is an agreed-upon (standard) method of converting the bits into characters or other types of data. There are many types of encoding that extend well beyond storing data. One example is morse code which was invented in the 1830s that encoded letters into dots and dashes that could be sent via blinking lights or intermittent sounds. There is a fun morse code demo if you want to see how letters get encoded (and even download an audio file). Another fun example is the punch card. This was the way characters were encoded into a machine-readable format. If you are curious, here is a cool punch card demo.

More modern examples include character encoding (ASCII and UTF-8 are common examples). These are just fancy ways of telling your browser when you load a webpage what character set it uses. Read this article if you want to know about what developers must know about Unicode and character sets. Also, you have most likely seen URL encoding where the address in your browser looks like HTTP://www.somewebsite.com/Special%20character-%204%20fun%40%20. This is an encoding scheme to allow special characters in your address bar without breaking it. My favorite form of encoding – and one you are probably most familiar with is QR codes. First created for the automotive industry, this has become more and more commonplace. Many advertisements, business cards, and mobile applications use QR codes. QR codes are simply encoding data into an image that can easily be read by a computer – which is really just a more advanced version of the ubiquitous barcode. You can create your own QR code here.
Obfuscation
Obfuscation is a method of hiding data by changing it in a way that it still can be used but isn’t easily read or understood by a person (or able to read at all). The intent is typically around improving security. In the context of Information Technology, there are three common ways obfuscation is used.

Source code obfuscation
Source code obfuscation refers to methods to limit or prevent third parties from understanding the code and using it to reproduce it or find weaknesses to exploit. There are many resources that explain the many ways this is done and is beyond the scope of this article. That said, the goal is to have the code work without exposing the details necessary to exploit it. One example is replacing variable names that are human-readable like “first_name”, “last_name”, “social_security”, “birth_date”, etc to “t”, “u”, “v”, and “x”. If you look at the code, you know what “first_name” is, but you won’t immediately know what “t” is. This essentially makes it harder for people to read your code and understand what it is doing. An example of this is the image of the Nachochess code. To learn more, here is a great article on code obfuscation with many examples. On the right is the 18th International Obfuscated C Code Contest (IOCCC) 2005 winner for the smallest chess game (code minimized which is a form of obfuscation).
Tokenization
Tokenization is when you replace a data element at rest with something else. An example is replacing someone’s first name with a code. You would do this when you want to have many people test without sharing private data. Instead of having the first names visible, they could be replaced with simple codes like name1, name2, name3, etc. Those names could be then traced back to the real name in the event you need that information later. Unlike other concepts, you can easily read tokens and they are unique in that some users are able to trace back to the original data to see what it was originally. There are many implementations.
For example, assume you have a database with personal data. The testing requirements are fairly strict (as they should be). You require:
- Substantial testing with multiple teams before going to production
- Testing teams do not have visibility to the data
- The testing must be done with millions of permutations between data points (a mixture of age, address, employment status, salary, marital status, hire date, etc)
- Hundreds of the tests have specific needs (find an employee who is over 40, married, lives in California, makes over 100k, etc)
- Etc (there are typically more requirements, but you get the idea)
How would you do this while hiding the data and simultaneously ensuring you capture all the data points you need? If you guessed tokenization, you would be correct. Essentially replacing personally identifying information with a token.
Data Masking
Data masking is where you take existing data like first names and replace it with data that looks real but is not like “John Doe”. This data typically cannot be traced back to the original data and is also used primarily for testing purposes. In other words, you would replace all of the real data with fake-looking data just to have data to test with that you aren’t concerned about privacy impacts. In this case, you would not be able to validate it back to the original source, and many times that’s desirable. If you have a common set of data that you test with over and over that is static and represents the data you have, and ties back to the test cases – you should be set. This set of data can be used over and over and be added to over time to make a complete set of fake data that you can test with over time. You can design the data in such a way that you have expected output each time you run the test.
Scrambled
Scrambled data is pretty much what it sounds like. If you have personal data like ‘First Name”, “Credit Card”, or “Password” and you want to have many testers work with that data but not see or know the data and you don’t have a need to trace it back, it is super easy to just scramble the data. That essentially means replacing the data with new data that is meaningless and irreversible. This is a one-way process like scrambling an egg. You can’t unscramble it and put it back into the egg. You can use an algorithm to perform this task as long as it sufficiently replaces the data with new data. There are many cases this is highly desirable when there are 100 columns of data in a table you need to test with and only 10 are useful in your test cases. The remaining data elements can be just scrambled to protect the original data.
Hashed
Hashing is a one-way cryptographic function that creates a unique fixed-length string. By design, the output is unique to the input in such a way that any changes to the input will have a different resulting output hash. This serves two common purposes.
One common usage of hashing is storing passwords. Every secure system does not store user passwords in plain text. In fact, not only do you not want to store them as plain text, but you also want that data ‘unrecoverable’ if you had access to it. At first glance, that really doesn’t make sense. If a user correctly enters their password how does a system ensure they entered it correctly if you can’t compare the password in the database to what was entered? The answer (if you haven’t guessed already) is hashing. When the password is first entered, it is hashed. Every subsequent time the user enters a password to gain access, the system hashes the entry and compares the two hashes. If they are the same, then the password matched. If you are wondering how if an attacker were to gain access to a list of userids and hashed passwords, how could that ever be used to reconstruct the original password? By design, you can’t ‘unhash’ an input. However, if you have a list of hashed passwords, you could hash a few million commonly used passwords and see if any hashed output matches. Again, if the input is the same, the output has to be the same as well. Furthermore, there are programs (like Jack the Ripper) that you can use pre-loaded passwords with hundred of thousands of passwords and automatically test them against hashed passwords and find the original passwords. This is why in my other post regarding passwords, you should always use unique and strong passwords for each system you create userid and passwords.
Another common usage of hashing is validation. For example, if you download software and want to ensure that the software hasn’t been altered in any way, you could check its hash (really known as a checksum or digital signature). It is the same process of using a cryptographic hash function that takes an input (file or string) and produces a string of a fixed length. Again, if there are any changes in the input, the output will be very different. Here is a fun exercise you can try to demonstrate this in action.
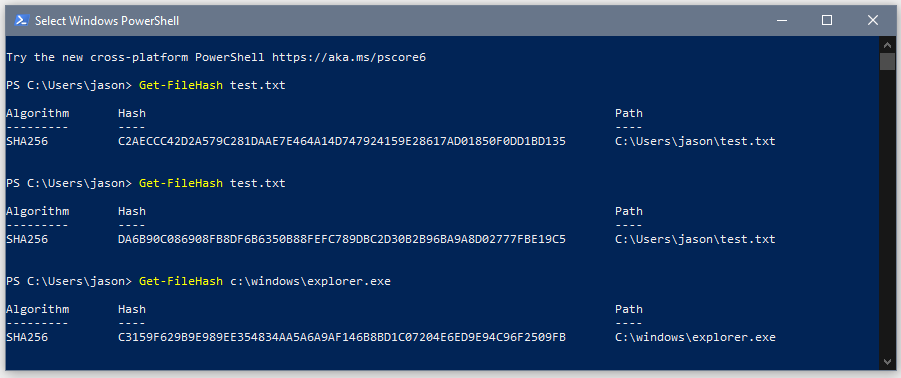
Here are the steps (using Windows):
- Open up File Explorer
- Browse to the folder with your name on it
- Should be below the documents folder
- You can also just type in C:\users\yourname
- Right-click and create a new text file and name it “test.txt”
- Open the file in notepad by double-clicking and type in “hello world” as the text of the file
- Save the file (leave it open)
- Click on Start, type in “Powershell”, and open windows PowerShell
- Run the command “Get-FileHash text.txt”
- Go back to the file and add a period at the end
- Save the file again
- Go back to PowerShell
- Run the command again by using the up arrow and pushing enter
- Look at how the hash has changed between the first and second time when all you did was add a period!
- For fun, you can also try other files like the explorer program by using “Get-FileHash C:windowsexplorer.exe”
Your results in PowerShell should be similar to the picture on the right. You also can notice that the hash is the same length if the file is a small 1 kb file or a larger 4,714 kb file. If you find a 100mb file, it will also be the same length with a unique hash.
Salted and Peppered Hashes
Salted and Peppered hashes are something you could order at Waffle House, and it also is a security measure. Considering the above example of storing user passwords in your database as simple hashes. There is no way to decode the hash to the original password. However, as above you can use a program to test hundreds of thousands (or millions if you have time) against the hash to find matches. You can then see which users use which passwords and all identical hashes have the same password. A recent example is the ParkMobiler breach. All of the passwords were exposed and it is claimed by ParkMobile that they are secure since they were salted.
Since many people use insecure passwords that have the same simple algorithm like “my1pass4Bank8675!” and then use another “my1pass4School8675!”. Both of those passwords follow the typical ‘use a long password with letters (uppercase and lowercase), numbers, and at least one symbol, and yet they are terrible. If this sounds like you, use a password manager and be safe. Just to drive home the point, the MD5 hash of “password123” is “482c811da5d5b4bc6d497ffa98491e38“. Every time you see that hash, you know that the original password was “password123”. This and millions of other common passwords are known hashes called rainbow tables. If you want to check, just google that hash – you will see nearly a thousand different results showing the original password. You can also easily generate your own hash of your own password and google the hash to see if it is also known.
Back to salting and peppering – these are tools that can be used to increase the complexity to gain the passwords from a table of hashed passwords.
Salting is taking a unique string for each user that is added to the end of the password (also known as concatenating) before hashing the password. Using this method, the extra ‘salt’ makes a rainbow table attack using known hashes useless. It also makes the hash generated from the same password unique for each user. This method has been proven so effective, it is built into many programming languages as a way to store passwords (and the like). For example, newer versions of PHP have the built-in function password_hash. In most cases, the salt is a known string that’s stored right with the hash in plain text in the database.
If you coded it yourself in python (one of my favorite languages), it might look like this:
Without salt:
password = "My1securepa55w0rd"
password = bytes(password, "utf-8")
hashed = hashlib.sha1(password)
With salt:
password = "My1securepa55w0rd"
salt = secrets.token_bytes(16)
salted_password = bytes(password, "utf-8") + salt
hashed = hashlib.sha1(salted_password)
Even if you aren’t a seasoned developer (see what I did there?), you can see how trivial it is to salt the password before hashing it. This is now a commonly used method of ensuring that the stored passwords in the database aren’t plain hashes that are known hashes available in rainbow tables.
Peppering is using a similar process but adding a string that’s not stored in the database. This is a string that’s typically stored on the server as an environment variable separate from the database. This prevents someone who has stolen the database the ability to break the hash with a rainbow table of hashes as the hashes will be unique to the server as the pepper has changed them all. The pepper is the same for all users and if used without salting, provides a minimal improvement in security.
Example with salt and pepper:
password = "My1securepa55w0rd"
salt = secrets.token_bytes(16)
pepper = os.environ.get('Pepper')
salted_password = bytes(password, "utf-8") + salt + pepper
hashed = hashlib.sha1(salted_password)Final touches on your perfectly seasoned data
As I’m writing about password security, hashing, salting and peppering, I remind you that in no case (no matter what), you should never attempt to ‘roll your own security algorithm’ outside of an academic exercise. There are a multitude of reasons, but just trust me that it is a bad idea. If you really want to understand why, the OWASP Foundation (which is a group of security experts) has many articles on this. Just don’t.
By now you should be a moderately seasoned professional who understands some of the data at rest security concepts including encrypting, encoding, obfuscation, scrambling, hashing, salting, and peppering.